필자는 최근들어 뒤늦게 수영을 배우고 있다. 처음 시작할 때는 물위에 육중한 몸을 띄운다는 것이 신기하고 어려웠다. 하지만 배움이 이어질수록 진짜 어려운 것은 물위에 뜨는 것이 아니라 오히려 사람 몸이 물속에 가라앉는 것이라는 사실을 알게 되었다.
그런데 오래전부터 전해 오는 “열 길 물속은 알아도 한 길 사람속은 모른다”라는 속담이 있다. 본래 뜻은 사람 마음을 알기가 어렵다는 의미로 이해되는 속담이지만 수영을 하다보니 오래전 사람들이 어떻게 사람 키에 열배가 되는 ‘열길’ 깊이에 물속을 알 수 있었을까 하는 궁금증이 생겼다. 요즘이야 잠수 장비도 좋고 심지어 들어가지 않고도 어군탐지기가 물속을 마치 영화 촬영하듯 보여준다. 하지만 수영하면서 경험한 바로는 내 키만큼 깊이에 들어가는 것도 힘들다. 그런데 도대체 10배의 깊이 속을 어떻게 알 수 있었을까.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 1](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_01-compressor-720x405.png)
50년 이상 낚시로 물에 빠져(?) 사셨던 아버지께 그 속담의 의미와 가능성을 여쭈었더니 몇 가지 이야기를 해주신다. 첫번째, ‘열길 물속을 안다’라는 말은 마치 지도를 그리듯 물 속의 지형을 안다라는 의미가 아니라 ‘물고기가 어디 있는지 안다’라는 뜻이란다. 두번째, 우리는 물고기가 헤엄을 치기 때문에 여기저기 돌아다닐 거라 생각하지만 사실 물속에서 물고기는 거의 비슷한 특정 환경에 주로 모여 있고 가끔씩 떼를 지어 정해진 곳으로 이동한다는 것이다. 다시 말해 물고기의 위치는 거의 변하지 않거나 변화한다해도 일정한 규칙성이 있다는 것이다. 세번째, 그러한 물고기가 있는 위치나 그들의 움직임은 오랜기간 수 많은 어부들이 고기를 잡는 과정에 습득된 지식이자 지혜라는 것이다. 듣고 보면 그것은 과거 시스템이 없던 시절에 존재한 바다의 ‘빅데이터’와 같은 것이다.
필자는 2천년대 초반, ‘빅데이터’라는 단어가 나오기 전부터 ‘데이터’ 분야에서 일을 했다. 금융 산업과 같이 오래전부터 데이터가 중요한 산업들도 있지만 필자는 ‘데이터’보다는 ‘감(感)’이 더 중요하게 여겨지던 패션 산업 분야에서 데이터에 대해 갓 눈을 뜨던 시기에 일을 했다. 그덕분에 패션 산업에서 데이터를 수집, 정제하고 분석하여 어떠한 의미있는 결과를 얻어내는 전체 프로세스가 성숙되어 가는 일련의 과정을 경험할 수 있었다. 초기 엑셀로 1만행 미만의 데이터를 분석하던 것이 대용량 데이터 베이스 시스템으로 성장해서 몇백만건 이상의 데이터 분석이 가능해졌고 마침내는 데이터 웨어하우스까지 구축하면서 그러한 데이터를 다양한 과점에서 조망해 볼 수 있는 입체적 분석의 체계까지 갖추어졌다. 그 결과 패션 산업에 다양한 경영자료에 필요한 숫자를 제공할 수 있었다.
그러나 데이터를 다루던 초기에는 어떤 이상(理想) 같은 것이 있었다. 바로 ‘한 사람에 대한 데이터를 충분히 모으면 그 사람에 대한 모든 것을 알 수 있게 되지 않을까’하는 것이었다. 개인의 다양한 정보, 키, 몸무게, 좋아하는 색깔, 선호하는 옷 스타일 등의 데이터를 수집하면 마치 물속의 지형도를 사진으로 찍은 것처럼 패션 고객에 대한 이해가 정밀하게 가능하게 될 것이라 생각했다. 하지만 오래지 않아 거의 불가능하다는 사실을 알게 되었다.
왜냐하면 ‘사람의 변화’하기 때문이었고 그 변화는 그 사람의 내적 특성뿐만 아니라 외부 자극에 의해 발생했기 때문이다. 쉽게 말해 한 사람의 옷을 입는 스타일은 상당히 불규칙적으로 변한다. 그런데 그 변화는 그 사람이 성장하면서 나타나는 신체적 변화보다는 세상 유행이라는 자극이 더 크게 작용한다. 따라서 한 사람에 대해 지극히 방대한 데이터를 모아도 그 사람의 행동, 특히 미래의 행동을 예측하는 것은 어렵다.
물론 고객에게 데이터를 확보하는 것도 쉽지 않았다. 개인정보를 보호해야한다는 윤리적인 지침이 아니더라도 그 고객의 옷장속 옷의 정보도 획득하기 어렵다. 얻을 수 있는 것은 그저 그 고객이 내가 일하던 브랜드에서 산 옷에 대해서만 알 수 있을 뿐이었다. 심지어 1년에 한 브랜드에서 2회이상의 옷을 사는 고객이 전체 고객의 20%정도 수준이다 보니 80%에 가까운 고객의 의류 구매데이터는 1년에 1건에 불과했다. 하물며 그 고객에게 영향을 끼치는 외부의 자극에 대한 데이터를 수집한다는 것은 거의 불가능하다고 생각했다. 그래서 비록 시스템은 커지고 복잡했지만 처음에 이상에 도달하기에는 턱없이 부족하다는 사실을 절실히 깨달았다.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 2](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_02-compressor-300x207.png)
그렇게 데이터를 통해 인간을 안다는 것이 거의 불가능하다는 사실을 실감할 때쯤 ‘빅데이터’라는 단어가 시장에 등장했다. 하지만 데이터의 한계를 절감하던 터라 그 등장에 그냥 시큰둥 했다. 그러던 어느날 구글이 검색 이력 데이터를 ‘Google Trends’를 통해 공개했다는 사실을 듣게 되었다. 과거 내가 다룬 시스템은 2~3백만의 고객이 일년에 1~2번정도의 데이터를 남겼던 것과 비교해 구글의 검색 기록 데이터는 전 세계 인구에 맞먹는 숫자의 사람들이 하루에도 몇십번씩 검색한 이력이 고스란히 담겨 있는 실로 엄청난 양의 데이터 였다. 그러나 처음에는 그게 무슨 의미가 있는지 깨닫지 못했다.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 3](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_03-720x358.png)
그러던 지난 2012년 대통령 선거 직전, 여론조사 발표가 금지된 이른바 깜깜이 기간에 사람들은 구글 트랜드 서비스에 몰려갔다. 구글이 보여준 결과는 박근혜 93, 문제인 84였다. 그리고 투표가 마무리된 시점 발표된 출구조사에서는 박 50.1%, 문 48.9%로 나왔다. 그런데 실제 투표함이 개봉되고 개표가 마무리 된 최종 결과는 박 51.6%, 문 48.0%로 출구조사보다 구글 트랜드의 결과가 더 정확하게 예측했다는 사실이 알려졌다. 그리고 뒤늦게 이보다 앞선 미국 대선에서 오바마와 롬니의 대선 결과도 구글이 멋지게 예측해 냈다는 사실도 듣게 되었다. (출처: “점쟁이 구글?… 韓-美대통령 당선자 족집게 예측”, 2012. 12. 21, 동아일보) 구글은 뭔가 달랐다. 내가 경험한 한 기업에 나름 규모있고 잘 정돈된 데이터와는 비교할 수 없는 어떤 것이 있었다.
앞선 기고에서 AISAS라는 소비자 행동이론을 살펴본 바가 있다. 이에 따르면 고객은 어떠한 행동에 앞서서 주목(Attention), 관심(Interest), 검색(Search)을 한다. 개별 고객이 어떤 것에 주목하고 관심을 갖는지 아는 것은 쉽지 않다. 4차 산업혁명에 있어서는 AR, MR등의 발전은 그러한 이상으로 다가가게 도와줄 수 있을 것이다. 그러나 검색의 단계는 어떠한가. 바로 구글, 그리고 우리나라의 네이버를 통해 이루어진다는 사실을 우리는 알고 있다. 그래서 구글이 구글 트랜드를 통해 자신들의 검색 이력 데이터를 공개한 것은 사실상 고객의 ‘검색’ 단계를 이해할 수 있는 빅데이터가 열린 것이다. 그래서 앞선 대선 결과 예측 같은 다양한 고객의 행동을 분석하고 심지어 예측할 수 있는 길이 열린 것이다.
그렇다면 패션 산업에서 데이터와 구글의 데이터는 무엇이 다른 것이었을까. 데이터의 내용 측면에서 구글은 검색(Search) 단계의 데이터를 보유하고 있고 패션 산업은 구매행동(Action)단계의 데이터를 부분적으로 가지고 있다는 점이 다르다. 하지만 더 큰 차이는 필자의 경우, 패션 데이터를 통해 한 사람을 알고 싶어했던 반면, 구글 트랜드는 한 사람이 아닌 여러 사람의 경향성을 이해하고자 했다. 필자의 경우 변화무쌍한 사람을 데이터만으로 아는 것은 거의 불가능했다. 마치 개울가에서 물고기 한마리 잡겠다고 이리저리 뛰는 모양새와 비슷하다. 그런데 구글은 한 사람이 아니라 일군의 사람들이 모여있는 집단의 움직임을 빅데이터를 통해 추적한다. 그 결과 어부들이 수면의 움직임이나 그물을 내린 결과 등을 통해 고기 떼의 위치를 감지하고 추적할 수 있었던 것과 같이 많은 수의 고객군에 대한 예측이 가능한 것이다.
이와 같이 개별적으로는 불규칙한 존재들이지만 서로 연결되어 영향을 끼치는 과정에서 크고 분명한 규칙을 드러내는 집단을 두고 복잡계(Complex System)라고 한다. 구글은 인간 집단속의 복잡계적인 특성을 인간 스스로가 제공하는 ‘관심의 표현(검색)’에 기반하여 추적하고 연구할 수 있게 해준다. 그래서 기존 개별 브랜드의 데이터와는 차별적이다. 게다 그러한 관심의 표현은 인간에게 아무런 제약 조건을 주지 않은 상태에서 자연스럽게 나온 것들이기 때문에 그 데이터를 연구하는 것은 심지어 ‘인간’ 자체를 연구하는 것이라 할 수 있다. 그래서 빅데이터는 인류의 가장 객관적 역사를 시스템에 써둔 역사책이며 그 적용이 신속하다는 차원에서 일종에 평행 우주라고도 볼 수 있다. 그래서 우리는 구글의 빅데이터를 통해 약간의 과장을 보태자면 전 인류의 생각을 읽어낼 수 있게 된 것이다. 그래서 관련 분야의 책 제목도 ‘구글신은 모든 것을 알고 있다’라고 지어질 수 있었던 것이 아닐까.
그렇다면 구글의 빅데이터가 도대체 무엇을 알고 있는지 실예를 통해 한번 살펴보자. 패션쪽에서 일하던시절 매년 연말 관리하는 브랜드가 포함된 시장에서 시장 점유율을 내년도 사업계획서에 반영하기 위해 구하느라 애를 먹었던 경험이 있다. 구글은 이런 것도 알려줄 수 있을까. 그래서 유명 글로벌 SPA 브랜드인 ‘유니클로’, ‘자라’ 그리고 ‘H&M’이 호주(오스트레일리아) 시장에서 어떤 실적을 보이고 있는지 한번 살펴보았다.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 4](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171213_4industry-compressor-720x400.png)
출처: 시장 점유율 (글로벌 무역 정보 블로그, https://goo.gl/2WvVPt), 관심도 지수 (구글 트랜드, https://goo.gl/kdA6r2)
호주의 패션시장에 대해서 아는 바가 없다. 그런 백지의 상황에서 그저 호주에 사는 사람이 구글에서 얼마나 검색해보았는지를 살펴보았다. ‘관심도 지수’는 쉽게 100명중 몇 명이나 구글에서 검색을 했는가 정도로 이해하면 된다. 그리고 한국의 한 블로그에서 밝힌 해당 브랜드의 호주 시장 점유율을 참고(https://goo.gl/2WvVPt)하였다. 그런데 위의 그래프를 보면 놀랍게도 그 결과가 시장 점유율과 거의 일치하는 것을 볼 수 있다. 이 정도라면 혹시 그 부지런한 블로거가 게으름을 피우더라도 구글 트랜드의 데이터만으로 시장 점유율 데이터를 추정해 볼 수 있다.
물론 호주의 데이터를 본 이유는 호주의 시장점유율 데이터만을 구할 수 있었기 때문이다. 만일 이 글을 읽는 독자중 국내 데이터를 갖고 있거나 혹은 자기 브랜드와 경쟁 브랜드의 경쟁 상황을 비교해보려면 구글 트랜드나 네이버 데이터랩을 통해 확인이 가능하다. 아마 이 두 서비스를 경험해 본 사람이라면 분명 이렇게 말할 것이다.
“안 들어가본 사람은 있어도 한 번만 들어가본 사람은 없다.”
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 5](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_05-compressor-720x492.png)
참고로 국내의 경우는 구글의 검색 시장 점유율이 40% 수준으로 네이버가 좀더 데이터가 많다. 하지만 네이버는 검색 결과 데이터를 약 2년여밖에 제공하지 않고 분석에 있어서도 제약이 좀 있는 편이다. 그러나 간단한 검색어 빈도 분석은 네이버 데이터랩을 통해서도 어렵지 않게 해 볼 수 있다.
빅데이터의 조건, 3V (Volume, Velocity, Variety)
여기까지 읽고 반가운 마음에 자신의 브랜드 이름을 위의 서비스에 넣어본 독자중에 누군가는 실망했을 수 있다. 왜냐하면 정확도가 그리 높지 않는 경우도 종종 존재하기 때문이다. 그래서 세상의 질문에 보다 정확하게 대답할 수 있는 빅데이터가 되려면 몇 가지의 조건을 충족해야한다.
첫번째는 데이터의 양(Volome)이다. 데이터양이 늘어날수록 규칙을 발견할 가능성이 높다. 그래서 그 규칙을 하나의 Insight로 얻을 수 있는 것이다. 그러나 만일 입력한 브랜드가 사실 크게 유명하지 않아서 수백명 정도에 의해 검색이 이루어지는 수준이라면 그 예측력도는 상대적으로 낮아진다. 예를 들어 국내 대통령 선거 데이터는 국민 전체가 관심을 가지기 때문에 정확도가 상대적으로 높았다.
그러나 만일 지역에 국회의원 선거를 예측하겠다고 출마자의 이름을 입력하면 사실상 그 정치인의 이름을 검색해 본 사람수가 얼마 없기 때문에 실제 결과와 상당히 동떨어진 결과를 보여주게 되는 것이다. 이는 마치 점묘화에서 점의 수가 늘어나면 이미지가 뚜렷해지는 반면 점의 수를 줄일 수록 이른바 모자이크 처리를 한 것처럼 이미지가 불명확해지는 것과 유사하다. 따라서 데이터의 양이 늘면 그만큼 예측의 정확성이 분명하게 향상된다.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 6](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_06-compressor.png)
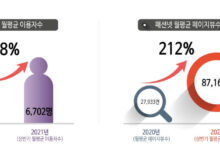
두번째는 신규 데이터가 발생하는 속도(Velocity)이다. 수많은 사람이 마음 속 생각은 끊임 없이 변화한다. 그래서 그러한 변화가 데이터가 반영되지 않으면 그 예측력은 당연히 낮아질 수밖에 없다. 그래서 데이터가 지속해서 빠르게 생성되어야 빅데이터 예측력이 높아진다. 실제 미국 질병통제예방센터(CDC)와 구글이 이와 관련해서 경쟁을 벌인 적이 있다. 해당 센터는 미국 전역의 독감 환자 현황을 주간단위로 수집했다.
그렇게 취합된 데이터를 통해 특정 지역에 환자가 늘어나는 경향을 감지해서 해당 지역에 백신을 공급하는 등의 활동을 통해 질병의 전국적인 확산을 막는 역할을 기획했다. 그런데 문제는 미국 전역의 데이털를 수집하는 데만 2주의 시간이 걸린다는 것이었다. 설령 본부에서 특정 지역에 이상징후를 발견한다고 해도 그것은 이미 2주전의 데이터라 대응이 늦어질 수 밖에 없었다. 이 상황에서 구글은 자신들의 검색어중 독감과 연관된 검색어, 예를 들어 감기약, 고열, 기침 등을 찾아 내었다.
그리고 실시간으로 이러한 검색어가 어느 지역에서 발생하고 있는 지를 조사하고 분석했다. 불과 수초면 데이터가 집계되고 분석의 결과가 나온다. (google flu trends, https://goo.gl/psioXk, 현재 업데이트 중단되었고 이유는 연구 블로그에서 확인할 수 있다.) 구글은 자신들의 과거 데이터 분석 결과와 질병 관리 기관의 조사 결과를 비교했더니 거의 틀리지 않는다는 사실을 확인했다. 결론적으로 구글 데이터의 신속한 업데이트 속도가 보다 정확한 독감 예측을 가능하게 한 것이다.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 7](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_07-compressor-720x382.png)
마지막 조건은 데이터의 다양성(Variety)이다. 사실 지금까지 살펴본 구글 트랜드나 네이버 데이터랩의 데이터는 검색어에 대한 검색 횟수가 숫자로 표현되는 데이터이다. 상대적으로 분석이 용이하다. 그러나 이렇게 숫자로만 표현된 데이터의 한계가 있다. 다음의 그래프를 한번 주목해보자.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 8](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_08-720x252.png)
(출처: 구글Trends, https://goo.gl/Rq7fsm)
지난 5년간 전세계에서 ‘유니클로’를 검색한 관심도 데이터 이다. 가운데쯤 그래프가 뾰족하게 솟아 있는 것이 보인다. 만일 동 기간에 다른 SPA브랜드와 비교를 했다면 유니클로의 실적이 단연 높다고 예측했을 것이다. 그런데 사실 저 시점의 검색은 ‘의류 브랜드 유니클로’에 대한 관심이 아니었다. 베이징시 유니클로 매장 탈의실에서 벌어진 불미스러운 동영상 스캔들이 그 원인이었다. 연일 전세계 미디어들은 관련 뉴스를 쏟아 내었다.
그 결과 해당 시점에 ‘유니클로’라는 검색어는 브랜드를 의미하는 것이 아니라 베이징에서 벌어진 스캔들을 의미했다. 그러나 구글 트랜드 상에서 ‘유니클로’라는 똑같은 Text로 분석 되기 때문에 이에 대해 분리하여 분석하는 것이 쉽지 않다. 최근 구글 트랜드는 분석 키워드를 단순 검색어, 브랜드, 제품, 등으로 구분하여 분석할 수 있도록 지원하고 있지만 사실상 정확하게 분리하여 분석하는 것은 거의 불가능하다.
동시점에 구글에서 유니클로라는 키워드를 검색한 이들이 마음으로 유니클로 옷을 검색하고 싶어 했는지 아니면 스캔들 뉴스가 보고 싶었는지는 그들만 알 수 있기 때문이다. 그래서 숫자만 봐서는 이러한 사실을 파악하는 것이 불가능하다. 이때 활용되는 것이 구글 트랜드의 ‘연관검색어’이다. 피크를 보이는 시점을 구글 트랜드에서 검색하면 해당 시점에 ‘유니클로’의 연관 검색어를 아래의 표와 같이 보여준다. 한눈에 보아도 관련 검색어가 의류 브랜드에 대한 관심이 아니라는 사실을 알 수 있다.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 9](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_09.png)
이와 같이 단순하게 숫자 데이터를 넘어 다양한 형태의 데이터는 단순 숫자 데이터에서는 발견하기 어려운 사실을 심도 있게 밝혀준다. 최근 인공지능 기술의 발달로 이제 이미지는 물론 동영상까지도 분석이 가능하게 되었다.
이와 같이 양, 속도, 그리고 다양성이라는 조건을 갖출 때, 데이터는 비로소 빅데이터로 보다 정확하고 정밀한 예측을 할 수 있게 된다. 그런데 이러한 빅데이터는 구글이나 네이버와 같은 검색엔진만 가질 수 있는 것일까. 물론 당연히 아니다. 이제 패션에서 활용가능한 몇가지 빅데이터 기반의 서비스를 살펴보고자 한다.
패션 빅데이터의 백미, EDITED
패션에서 빅데이터라고 하면 가장 먼저 ‘EDITED’라는 회사를 주목해 볼 필요가 있다. 이미 여러 매체를 통해 소개되어 이미 패션인들 사이에서는 WGSN만큼이나 유명해졌으리라 생각한다. 이들의 가장 큰 차별점은 패션의 트랜드를 읽어냄에 있어서 기존의 인적 전문가 기반의 분석이 아닌 철저한 데이터 중심의 분석의 입장을 취하고 있다는 사실이다.
우선 그들의 기본 Concept은 이러하다. 과거 패션 산업에는 비밀이 많았다. 디자인이나 가격정보등이 노출되는 것을 극도로 꺼려했다. 그러나 3차 산업혁명이라 불리는 정보화, 인터넷 혁명을 통해 패션은 전자 상거래의 영향을 가장 크게 받은 산업분야중에 하나가 되었다. 이제 패션 산업은 인터넷을 통해 옷을 판다. 이를 위해서 고객이 온라인에서 해당 옷을 더 잘 이해 할 수 있도록 사진이며, 가격, 사이즈, 컬러 Variation 등의 정보를 그들의 쇼핑몰을 통해 고스란히 노출하고 있다. 게다 그들은 온라인에서 신제품 출시 사실을 알리고 세일 공지를 올린다. 쉽게 말해 과거 기업의 비밀이라 생각했던 정보들이 인터넷에 그대로 노출되고 있는 것이다. EDITED는 이점에 주목했다. 그들은 전세계 9만여개의 쇼핑몰의 데이터를 주기적으로 긁어모은다. 기술적 용어로 크롤링(Crawling)이라고 한다. 그 대상은 고객이 눈으로 볼 수 있는 거의 모든 정보이다. 그래서 EDITED는 여기서 얻은 정보를 데이터로 변환한다. 혹시 EDITED가 제공하는 데이터가 어떻게 만들어지고 운영되는지 좀더 자세한 사항을 알고 싶다면 다음의 링크를 방문해 보길 추천한다.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 10](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_10-compressor-720x608.png)
그렇게 수집된 데이터는 일군에 빅데이터를 이룬다. 그리고 이 데이터를 기반으로 다양한 관점의분석 insight를 제공한다. 예를들어 EDITED는 시장내 브랜드별 복종(상의, 하의, 액세서리 등) 구성이 어떻게 되는지 분석하여 제공한다. 물론 브랜드마다 복종 카테고리를 구성하는 이름이 다르다. 그러나 한번쯤 사람을 통해 표준 카테고리와 브랜드별 카테고리를 매칭하거나 최근에 발전된 이미지 인식 기술을 통해 옷의 사진을 통해 그 옷의 표준 복종 정보를 얻어 내는 것도 가능하다. 또한 이미지 정보를 통해 옷의 컬러 정보나 스타일 정보를 추출하는 것도 가능하다. 그 뿐 아니다. 쇼핑몰에는 당연히 의류 가격이 표현되어 있다. 이런 데이터와 복종 데이터를 모아서 보여주면 복종별 가격 Range 데이터를 보여주는 것도 가능하다. 심지어는 브랜드별로 시즌별 신규 옷이 언제쯤 출시가 되는지, 그리고 그 옷들이 대략 언제쯤 세일에 들어가는가에 대한 일정도 데이터화하여 보여 줄 수 있다.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 11](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_11-compressor-720x277.png)
이와 같이 EDITED는 온라인상에 누구에게나 공개된 쇼핑몰의 다양한 형태 데이터(이미지, Text, 숫자, 날짜 등)를 기반으로 어떠한 패션 전문가도 하지 못했던, 가장 정확한 패션산업의 팩트를 일목요연하게 정리하여 제공해주고 있다.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 12](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_12-compressor.png)
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 13](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_13-compressor-720x239.png)
이런 일련의 일에 경험 많은 패션 전문가가 많이 필요하지 않다. 데이터 크롤링을 할 수 있는 프로그래머, 데이터를 정제하여 저장하는 데이터 전문가면 빅데이터 구축은 거의 가능하다. 단지 최종적으로 이를 패션인들에게 익숙한 언어와 표현으로 전환하는 것 정도는 경험있는 패션 전문가의 몫이 될 것이다. 최근들어서는 트랜드 분석 시장에서 유명한 WGSN도 이와 같은 빅데이터 기반의 정량 데이터 분석 서비스를 제공하고 있다.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 14](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_14-compressor-720x408.png)
고객이 쏟아내는 소셜 빅데이터의 분석, BUZZINSIGHT
이 시간에도 많은 사람들은 페이스북, 인스타그램, 블로그, 카페 등에서 우리 브랜드에 대해 이야기를 나누고 있다. 당장 네이버에서 우리 브랜드 이름으로 검색을 하면 수많은 결과들이 쏟아진다. 보통 우리는 맨 첫페이지의 결과를 대충 눈으로 훑어 보는 정도다. 하지만 그 속에는 우리 브랜드를 대하는 고객의 마음이 고스란히 담겨 있다. 그러나 이와 같이 텍스트, 이미지, 숫자, 링크 등으로 구성된 빅데이터를 일반 기업에서 크롤링을 통해 분석하는 것은 쉽지 않다.
그래서 이러한 소셜 빅데이터 분석을 전문으로 해주는 서비스들이 다수 등장하고 있다. 이와 같은 서비스의 특징은 앞서 본 서비스들과 같이 분석의 틀이 갖추어진 정형 분석보다는 그때 그때 분석하고 싶은 다양한 주제에 맞게 기민하게 대응하는 비 정형 분석의 유형을 띄는 경우들이 많다. 그래서 이 분야의 분석은 제공되는 시스템을 이용하기 보다는 분석의 주체인 브랜드가 무엇을 분석하고 싶은지를 우선 뚜렷하게 정의하는 것이 중요하다.
사실 이 분야에는 상당히 많은 국내 업체가 경쟁을 하고 있다. 게다 앞서 밝힌대로 시스템 중심이 아니라 의뢰자의 Business Question이 얼마나 잘 구체화 되어 있는가와 만나게 되는 업체 담당자의 경험이나 실력이 얼만큼인가이가 결과의 성패를 좌우한다. 그렇다 보니 어떤 업체의 서비스가 좋다 나쁘다를 평하기는 어렵다. 그럼에도불구하고 그 중에서 필자가 직접 경험해 본 서비스인 버즈 인사이트(Buzz Insight)를 소개 한다.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 15](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_15-compressor-720x585.png)
Buzz Insight의 경우는 마치 특정 목적에 설문조사를 하듯 특정 목적으로 특정 기간에 온라인에서 쏟아지는 소셜 데이터를 분석할 수도 있다. 또한 특정 카페, 블로그, 커뮤니티를 지속적으로 모니터링하면서 해당 커뮤니티에서 우리 브랜드에 대해 나오는 이야기들을 분석한다. 또한 의미 분석 기능을 통해 똑같이 우리 브랜드가 언급된 경우라도 긍정적으로 언급했는지 부정적으로 언급한 것인지를 구분하여 분석을 제공하고 있다.
다시 한번 강조하지만 소셜 빅데이터 분석을 제공하는 서비스는 많다. 실제 이용시에는 보다 다양한 업체와 상담을 통해 좀더 적합한 업체를 선택할 것을 추천한다.
우리 쇼핑몰 방문 고객 행동의 빅데이터 분석, Google Analytics
이제까지 예를 든 빅데이터는 대부분 회사 밖에 있는 데이터를 다루었다. 왜냐하면 회사내 데이터가 양, 속도, 다양성이라는 조건에 맞는 경우가 별로 없기 때문이다. 그런데 적어도 양적으로는 상당한 데이터가 나오는 서비스가 있다. 그것이 바로 고객의 웹행동 데이터다. 한 고객이 온라인 쇼핑몰에 들어와서 물건을 한번 사기 위해서 수~수십 페이지의 쇼핑몰을 돌아다닌다. 그리고 그러한 고객들의 행동을 모아 보면 훌륭한 빅데이터가 된다. 이를 통해 어떤 페이지에 사람들이 많이 방문하는지, 옷을 구매하는 절차에서 어떤 페이지에서 많이 이탈하는지, 심지어 디자인적으로 고객들이 더 선호하는 디자인이 어떤 것인지 등을 분석할 수 있다.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 16](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_16-720x393.png)
이러한 웹행동 빅데이터 분석을 용이하게 해주는 서비스가 바로 구글의 구글 애널리틱스(Google Analytics) 서비스이다. 해당 홈페이지에 가입을 하고 관련된 정보를 제공하면 통해 고객들의 행동을 구글 서비스로 전송하기 위한 스크립트를 받을 수 있다. 그리고 이 스크립트를 우리 홈페이지에 심기만 하면, 즉시 온라인에서 웹행동 분석이 가능하다. 해당 서비스를 통해 분석할 수 있는 내용은 책을 한권 써야할 만큼 방대하고 다양하다. 게다 지금 이 시간에도 분석 리포트는 계속해서 진화하고 있다. 따라서 필자는 혹시 온라인 쇼핑몰을 운영하면서도 해당 서비스를 모른다면 지금 당장 이 서비스에 가입하고 활용해보기를 추천한다. 게다 무려 공짜다.
고객의 오프라인 행동을 빅데이터에 담다. WALK INSIGHT
마지막으로 살펴볼 빅데이터 사례는 국내 스타트업인 조이 코퍼레이션의 워크 인사이트(WALK INSIGHT)이다. 패션 산업의 온라인화, 온라인 쇼핑몰 판매가 늘어나고는 있지만 여전히 오프라인의 매출도 무시할 수 없는 수준인 것이 사실이다. 그러나 오프라인 매장에 동선을 설계하고 전시를 하는 일인 VMD의 업무는 여전히 감(感) 중심으로 이루어지고 있다. 그래서 해외의 경우는 매장내 고객의 동선이나 체류 시간등을 WIFI나 CCTV 영상 분석 등 여러 방법을 통해 분석하고 최적의 결과를 도출하려는 시도가 있었다..그러나 사실상 그 정확도가 상당히 낮아 실제 비즈니스에 도움을 주는데 한계가 있었다. 그런데 최근 한 국내 스타트업이 이러한 데이터의 정확도를 보다 정확하게 끌어 올렸다는 평가를 받고 있다.
![[Industry 4.0] Part3 빅데이터, 한 길 사람 속은 몰라도 만명 사람속은 안다 | 17](http://www.fashionseoul.com/wp-content/uploads/2017/12/20171214_4industy_17-compressor-720x461.png)
원리는 간단하다. 매장에 WIFI 신호를 측정하는 센서를 설치하고 고객들이 들고 있는 스마트폰의 동선을 추적하는 것이다. 해외의 경우 WIFI 기반으로 검색하는 것이 거리 오차가 큰 반면 해당 센서는 상당히 정확한 측정이 가능하다. 대형 매장의 경우 이를 통해 진열대 사이의 동선에 고객이 어디서 머무르고 어떻게 이동하는지를 수치화된 데이터로 분석이 가능하다. 게다 매장 출입문 인근에 센서를 설치하면 매장앞으로 지나는 유동 인구에 대한 분석도 가능하다.
이렇게 쌓인 데이터를 기반으로 마케팅 Funnel 분석 (유동고객>방문 고객>진열대별 체류 고객>구매고객으로의 전환 분석)은 물론, 매장의 Zone 구성별 고객 행동 유형 분석, 오프라인 프로모션 효과 분석 등 다양한 분석을 제공해준다. 브랜드는 이러한 인사이트를 통해 오프라인 매장의 공간을 효율적으로 활용할 수 있는 전략을 수립하고 실행하는데 필요한 도움을 받을 수 있다. 현재 국내 유수의 화장품 브랜드, 백화점, 의류 매장 등이 해당 서비스를 도입하여 오프라인 매장 운영에 활용하고 있다.
이제까지 빅데이터가 무엇인지, 그리고 패션과 관련되어 어떻게 활용되고 있는 지를 살펴보았다. 이제 마지막으로 패션산업에서 빅데이터를 제대로 활용하기 주의해야할 몇가지를 살펴 보려고한다.
첫 번째, 애초에 패션산업은 ‘데이터’가 아니라 ‘감(感)’의 비즈니스였다는 사실을 기억해야 한다. 자칫 빅데이터의 유행이 몰고 온 ‘데이터’ 혹은 정량적 결과물에 대한 신뢰가 기존의 ‘감(感)’과 대결구도를 그리는 형태로 나타나지 않도록 주의해야한다. 지난 기고의 제목처럼 빅데이터 역시 아직은 ‘출발점’에 불과하다. 결과물이 거칠다. 데이터가 말하는 바대로만 비즈니스를 운전해가기에는 위험이 따른다. 따라서 아직은 ‘빅데이터’가 이야기해주는 팩트들은 기존에 감을 지닌 패션 전문가를 통해 정제되어야 한다. 아직 데이터가 이야기 하는 결과를 그대로 받아들이고 신뢰하여 비즈니스에 활용하기 보다는 우선 전통적인 패션 전문가들에게 제공되어 데이터 분석의 결과물이 시장에서 활용될 수 있는 인사이트로 성숙되어야 한다. 그리고 그 과정에서 패션전문가 스스로가 그 데이터를 신뢰하고 인정할 수 있게 되어야 한다. 그래서 ‘일은 사람이 한다.’라는 명제는 언제나 옳아야 한다.
두 번째, 그럼에도 불구하고 ‘데이터’를 믿어야한다. 과거 패션산업에서 데이터 관련 일을 할 때, 많은 이들로부터 받은 이런 이야기를 들었다. “니가 책임질꺼야?” 데이터와 전문가의 생각이 다를 때에 백이면 백 나오는 이야기였다. 그 현장에서 어려운 단어인 ‘인지부조화’라는 단어를 배웠다. 현실이 내 생각과 다를 때, 현실을 받아들이는 것이 아니라 오히려 현실과 다른 자신의 생각을 강화해 버리는 것이다. 물론 데이터가 항상 옳은 것은 아니다. 자체 데이터는 부족한 경우가 있고 구글의 데이터도 가끔 언론등에 의해 오염되는 경우가 있다. 하지만 분명한 것은 데이터는 거짓말을 하고 있지 않다는 것이다. 그래서 데이터 분석 결과에 대해 그러한 결과를 만든 데이터가 충분했는지 적절했는지는 토론 할 수 있지만 애초에 자신의 생각이라는 큰 바위를 세워두고 데이터로 그 바위를 깨라는 식의 접근은 삼가해야 한다. 다시 한번 말하지만 데이터는 패션 전문가를 돕는 가장 훌륭한 조수이지 결코 경쟁자가 아니다.
마지막으로, 빅데이터에 대한 활용은 기본적으로 밖에서부터 안으로 접근할 필요가 있다. 패션시장에서 데이터는 타깃 시장에 대한 분석과 이해 차원에서 빅데이터를 먼저 활용하는 것이 필요하다. 물론 이미 시장에서 일정 수준 이상의 인지도를 보유한 대형 브랜드라면 사정이 다를 수 있다. 하지만 론칭 초기나 혹은 단일 브랜드로 시장에 진입하고 있는 단계의 브랜드는 사실상 내부에 분석할 데이터가 부족하다. 또한 외부에서도 인지도가 낮고 회자되는 정도가 적어 빅데이터 를 통해 인사이트를 끌어내기에는 데이터양도 적다. 그래서 초기에는 외부 시장 이해의 관점에서 빅데이터 활용이 필요하다. 실제 패션 중소 기업중 빅데이터 활용으로 회자되는 수제화 메이커 ‘칼렌시아’의 경우에도 브랜드 자체를 이해하기 위해 빅데이터를 활용한 것이 아니라 그들이 목표로 하는 시장의 고객들을 이해하는 용도로 빅데이터를 활용하였다. 빅데이터를 통해 시장을 제대로 이해해서 시장내에서 성공을 거두어야 한다. 그래서 사람들 입에 오르내리는 브랜드로 성장해야 한다. 그리고나서 브랜드를 이해하는 방편으로 빅데이터를 활용해도 늦지 않다. 다만 예시로 든 구글 애널리틱스와 같이 내부에 이미 충분한 데이터가 확보된 경우라면 초기에 활용하는 것도 필요하다. 무료에 데이터 관리 비용이 전혀 들지 않는데 굳이 뒤로 미룰 필요는 없다.
이상으로 4차산업혁명의 주요 화두중 하나인 ‘빅데이터’에 대해 살펴보았다. 다음에는 빅데이터를 먹고 무럭무럭 성장하고 있는 ‘인공지능’에 살펴볼 것이다.
![[이응환 칼럼]마케팅 4P 프레임으로 본 패션 4차 산업혁명 | 18](wp-content/uploads/2018/02/cover-390x220.jpg)
![[Industry 4.0] Part3 인공지능, 내 일자리 빼앗을까? | 20](wp-content/uploads/2017/10/2016-06-10_kfashion-390x220.jpg)